

How Neural Networks Actually Calculate Word Relevance: The Query-Key-Value Mechanism
Understanding the elegant mathematical system that lets AI decide which words matter most

In our previous article on softmax, we saw how neural networks convert raw attention scores into clean probability distributions. We looked at examples like this:

But we glossed over a crucial question: where do those raw attention scores actually come from? How does the network calculate that “grandmother” deserves a score of 4.8 while “My” only gets 1.2?
The answer lies in one of the most elegant mechanisms in modern AI: the query-key-value system. This is the missing piece that connects vector embeddings to attention scores, and understanding it reveals how neural networks truly “decide” which words matter most.
Let’s continue with our same example “My grandmother bakes incredible cookies” and see exactly how the network calculates relevance between words using real mathematical operations, not just conceptual hand-waving.
How Words Calculate Relevance to Each Other
Neural networks use a three-part system called query-key-value attention. Think of it like a smart database lookup where each word plays three different roles simultaneously.
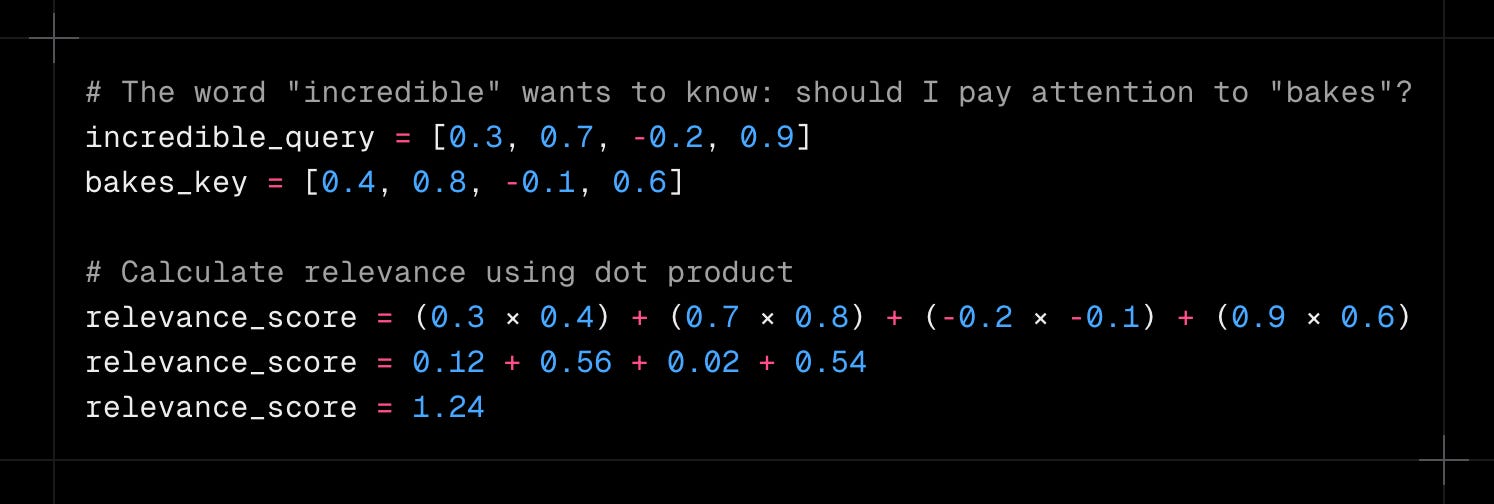
The dot product of incredible_query and bakes_key measures how aligned two vectors are. When query and key vectors point in similar directions, you get a high score (high relevance). When they’re perpendicular or opposite, you get a low score (low relevance).
The network does this calculation between “incredible” and every other word in the sentence:

This produces the raw attention scores we’ve been working with:

The Complete Attention Flow
Convert each word’s embedding into query, key, and value vectors
“incredible” calculates attention scores with all words. All other words repeat the same
Apply softmax with temperature to get attention weights
Use these weights to combine the value vectors

The final output for “incredible” is a weighted combination that emphasizes information from “bakes” (42% weight) and “cookies” (35% weight), with smaller contributions from the other words. This makes perfect sense because “incredible” is an adjective that modifies both the baking action and the resulting cookies.
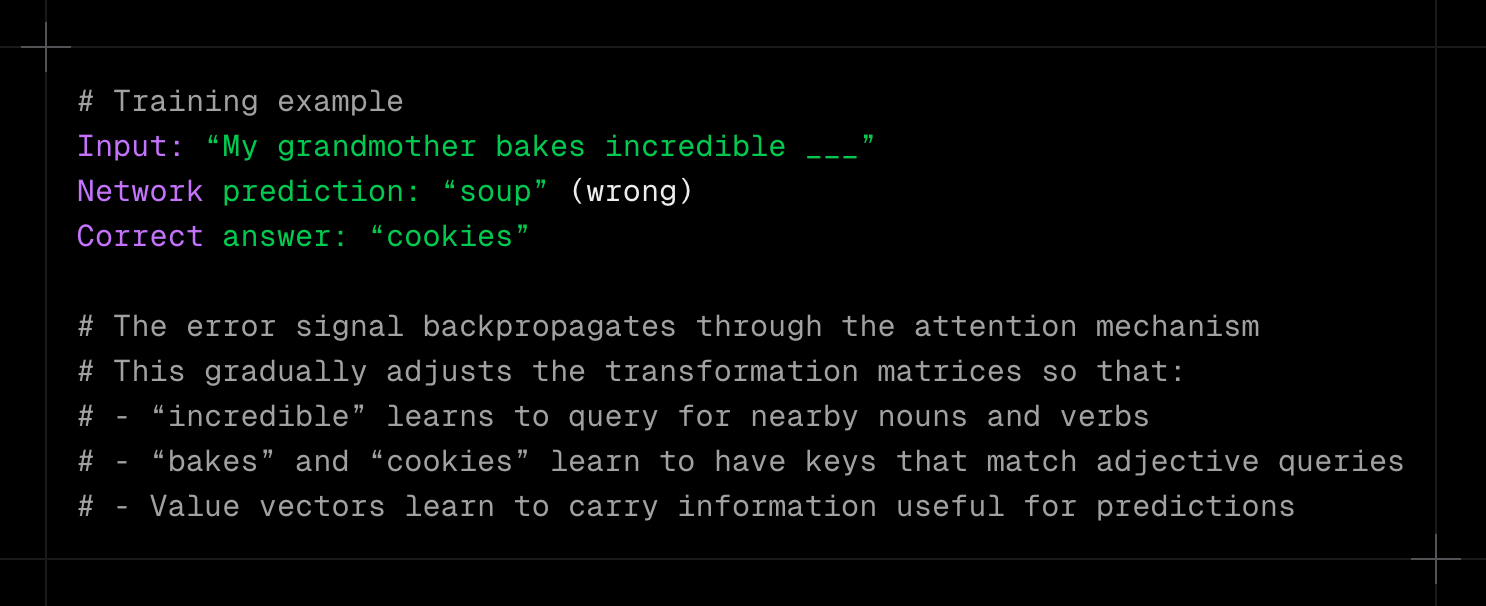
How the Network Learns What’s Relevant
You might wonder how the network knows that adjectives should pay attention to the nouns and verbs they modify. It learns this from data during training.
The network starts with random query, key, and value transformation matrices. As it processes millions of sentences and tries to predict masked words or next words, it receives feedback on its predictions:
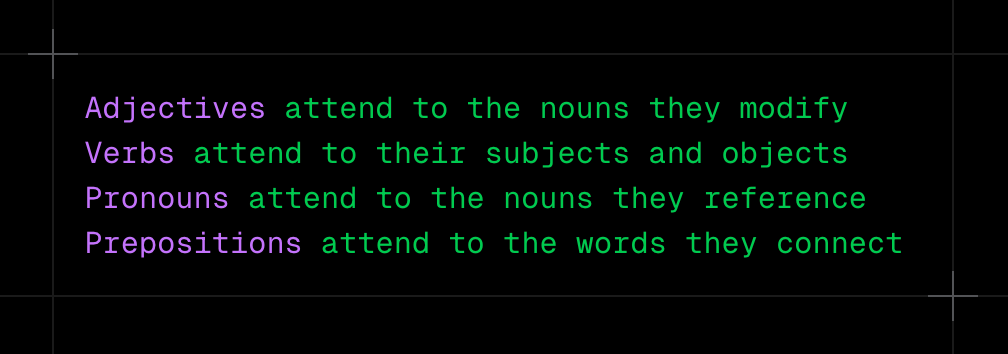
Over millions of examples, the attention mechanism becomes remarkably skilled at discovering relevant relationships. The network learns grammatical patterns like:
But it also learns semantic and contextual patterns that go beyond simple grammar rules. The same word “incredible” might attend to different words in different contexts:

Why This Three-Vector System Works So Well
The separation into query, key, and value vectors creates powerful flexibility:
Context sensitivity means the same word can play different roles. “Bakes” in “grandmother bakes” has a different key vector than “bakes” in “the bakes were delicious” because the embedding itself changes based on surrounding context.
Learned specialization allows queries to learn what to look for and keys to learn how to be found. An adjective’s query naturally learns to match with noun and verb keys without being explicitly programmed to do so.
Information routing through value vectors means attention weights control what information flows, not just which words are considered. The value vector can encode “this word is an action” or “this word is a subject” in ways optimized for the task.
Differentiable operations throughout the entire process means the network can learn through standard backpropagation. Every matrix multiplication and dot product has smooth gradients that flow backward during training.
The Bigger Picture
This query-key-value mechanism is what made transformer models so successful. Earlier attention mechanisms existed, but this particular formulation scaled beautifully. The same mechanism works whether you’re processing:
Each word independently calculates attention to every other word using the same query-key-value process. This parallel processing is what makes transformers both powerful and efficient on modern hardware.
When you read that GPT or BERT uses “multi-head attention,” it means they run this entire query-key-value process multiple times in parallel with different transformation matrices. One attention head might learn to focus on grammatical relationships, another on semantic similarity, and another on long-range dependencies.
The elegance of this system lies in its simplicity. Three linear transformations, some dot products, and a softmax create a mechanism that can learn virtually any type of relevance relationship from data. No hand-coded rules about which words should attend to which others. Just learned patterns that emerge from the structure of language itself.
This is why we can confidently say the network “understands” that “incredible” should pay attention to “bakes” and “cookies.” It’s not magic or consciousness. It’s a learned mathematical relationship encoded in the query and key vectors, discovered through exposure to millions of examples of how humans actually use language.
The Elegance of Learned Relationships
The query-key-value mechanism is one of those ideas that seems obvious in hindsight but took years of research to formalize. The specific formulation we use today was introduced in the 2017 “Attention is All You Need” paper by Vaswani et al., which became the foundation for transformer models.
What fascinates me most about AI and LLMs isn’t just their capability to boost productivity by 10x or 100x. It’s the research journey behind every component. The attention mechanism itself has roots going back to earlier work in neural machine translation, evolving through multiple iterations before arriving at the elegant query-key-value system we use today.
I’ve just started exploring the fundamentals of LLMs and the innovations that brought AI to where it stands today. Each concept, from attention mechanisms to temperature control, represents years of research and refinement. I’ll continue sharing these learnings in clear, practical language with real code examples.
Subscribe to follow along as we unpack the building blocks of modern AI, one elegant mechanism at a time.
