

Building Supabase Filters That Actually Work
From Naive Chains to Production-Ready Patterns: A Deep Dive into Complex Query Building for PostgreSQL.

Supabase promises database queries that "just work."
But every developer knows the truth: filters break, performance crawls and what looked simple in the docs becomes a debugging nightmare at 2 AM.
I've spent months untangling Supabase filter chains in FUT Maidaan, discovering patterns that transform fragile queries into bulletproof data pipelines.
Here's the exact system I use to build filters that handle millions of rows without breaking a sweat.
If you are figuring out what is FUT Maidaan then discover yourself by downloading the app.
The Monster We're Dealing With
Before we dive in, let me show you the complexity we're tackling. This is a real filter function from FUT Maidaan - a football player database with thousands of cards:
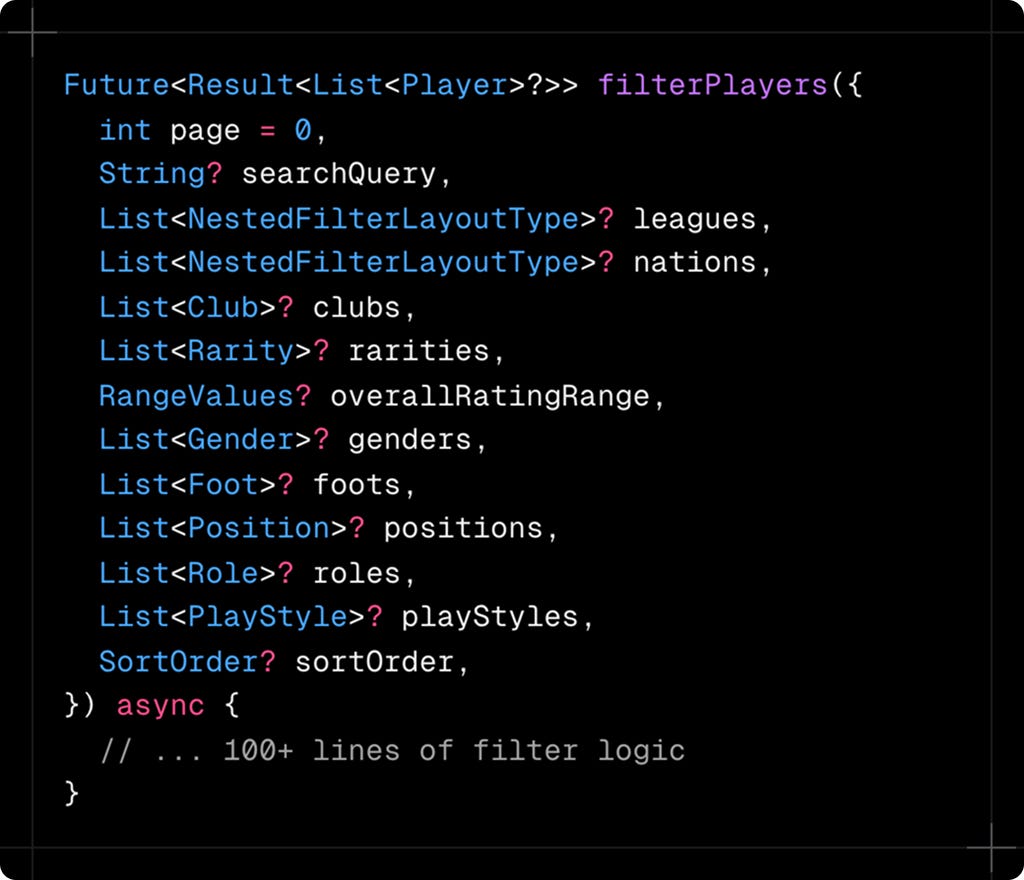
That's twelve different filter types. Users can search for "left-footed Brazilian strikers from Premier League with 85+ rating who have the Finesse Shot playstyle." And they expect instant results.
If you're thinking "just chain some .where() calls," you're in for a world of pain. Let me show you why and more importantly, how to build this correctly.
The Domain: Understanding Football Card Filtering
In FUT Maidaan, players have multiple attributes that users want to filter by. A player card isn't just a name and rating - it's a complex entity with leagues, nations, positions, special abilities (roles and playstyles) and various ratings. Users might want to find specific combinations like "German midfielders from Bayern Munich with the Deep-Lying Playmaker role."
This creates unique challenges. A player can have multiple roles and playstyles. Positions aren't just simple strings - they're hierarchical (a striker can play as center forward, right wing, or left wing). And users expect to combine all these filters seamlessly.
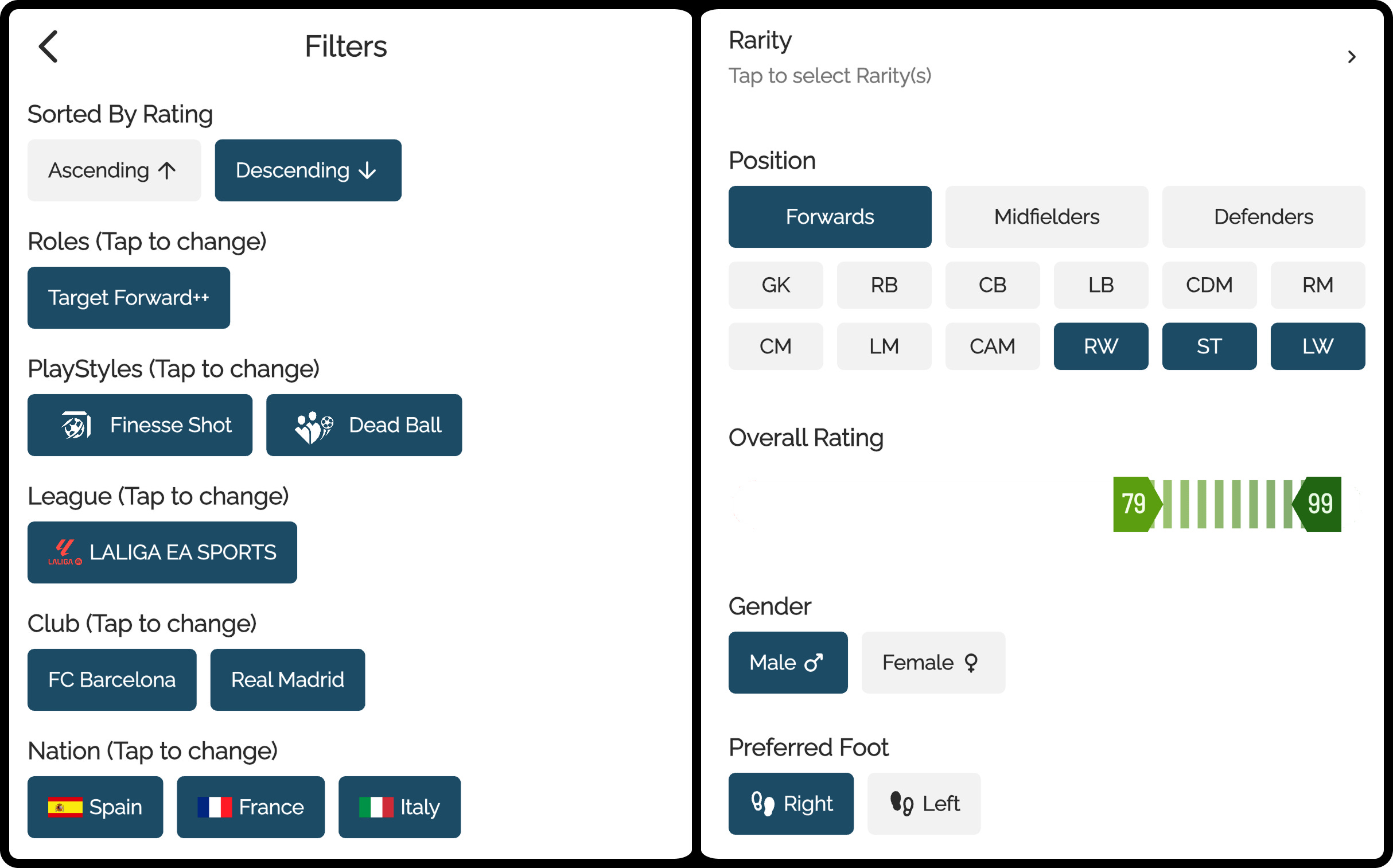
The Naive Approach (And Why It Fails)
When I first started, I tried the obvious approach:
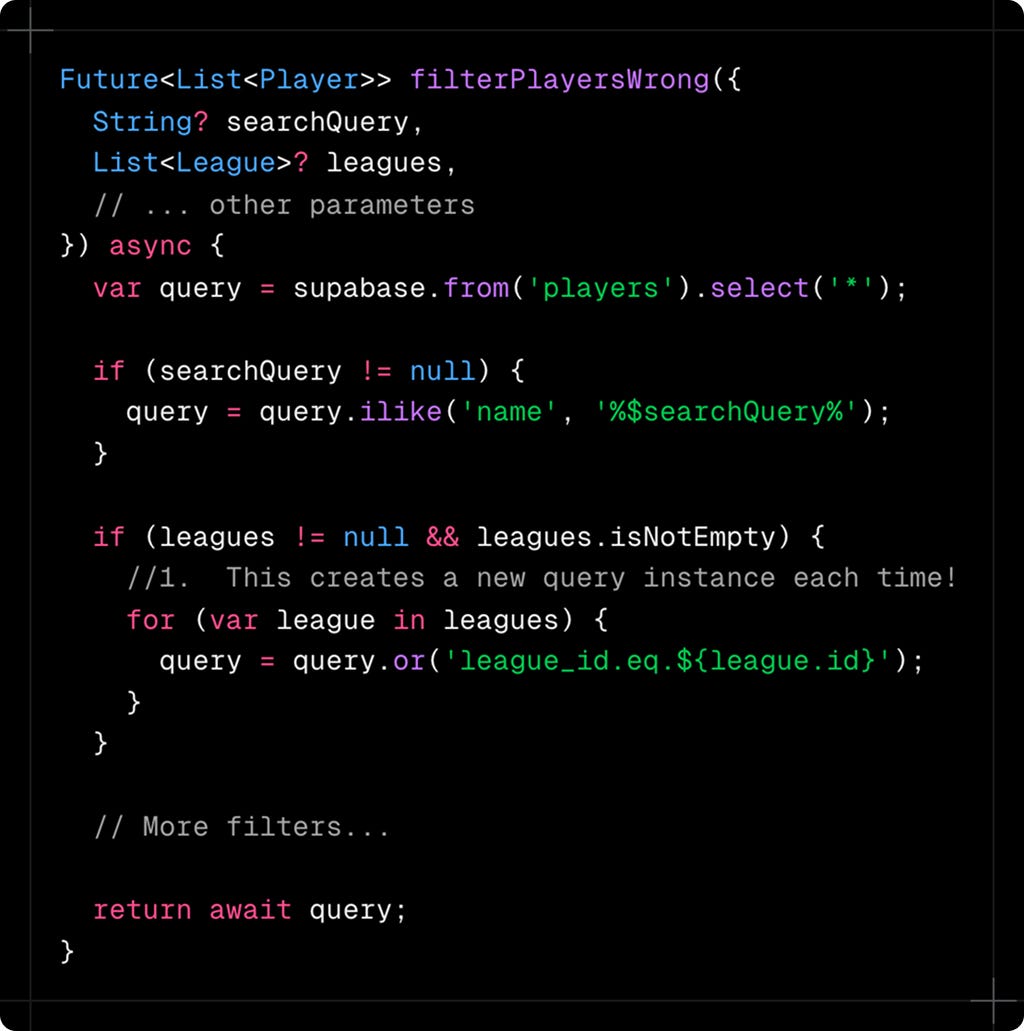
This approach has several problems. First, chaining .or() conditions creates increasingly complex SQL that Postgres struggles to optimize. Second, each method call might create a new query instance, leading to unexpected behavior. Third, there's no clear pattern for handling different filter types - some need OR logic, others need AND and some need special operators like contains for arrays.
The PostgrestFilterBuilder Pattern
The key insight is treating your query as a mutable builder object. Here's how the correct approach starts:
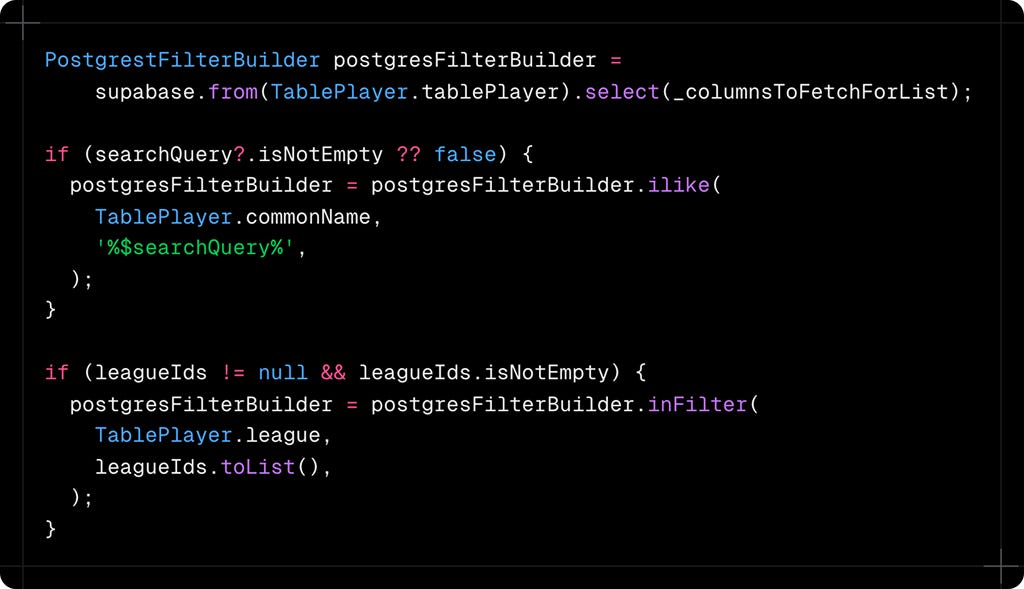
Notice how we're reassigning postgresFilterBuilder each time? This ensures we're always working with the latest query state. It's like building with LEGO blocks - each filter adds another piece to your structure.
Handling Multiple Values: The inFilter Magic
Here's where things get interesting. When users select multiple leagues or clubs, you need to find players in ANY of those selections. The naive approach uses OR chains but there's a better way:
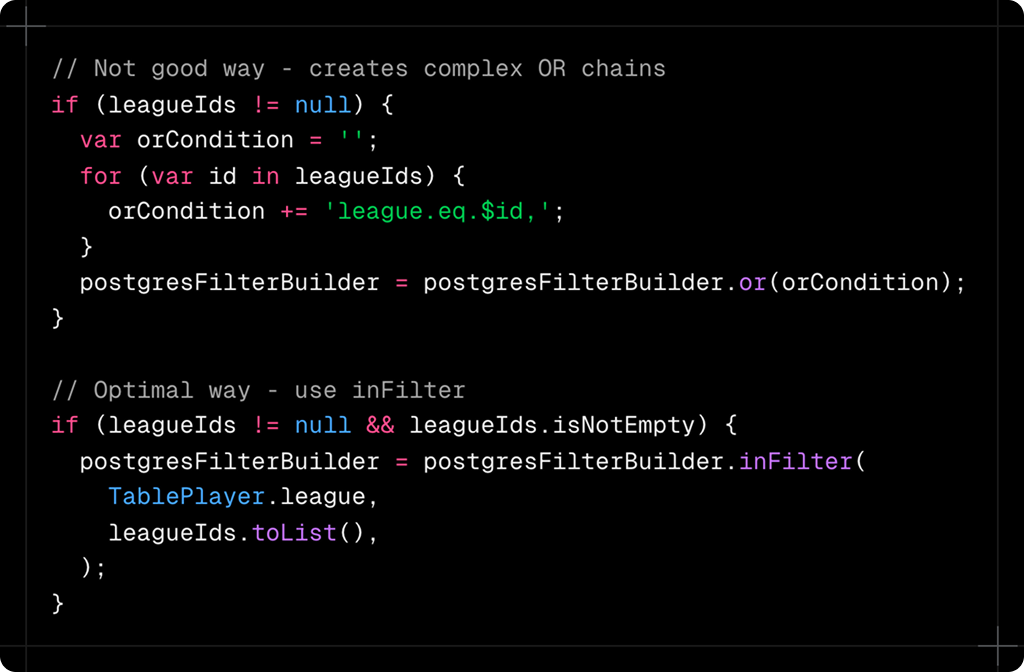
The inFilter method translates to SQL's IN operator, which Postgres optimizes much better than multiple OR conditions. It's cleaner, faster and less error-prone.
The Array Contains Pattern for Complex Filters
Now here's where it gets really interesting. In FUT Maidaan, players can have multiple roles and playstyles. These are stored as arrays of ids in the database. How do you filter for players who have ANY of the selected roles?
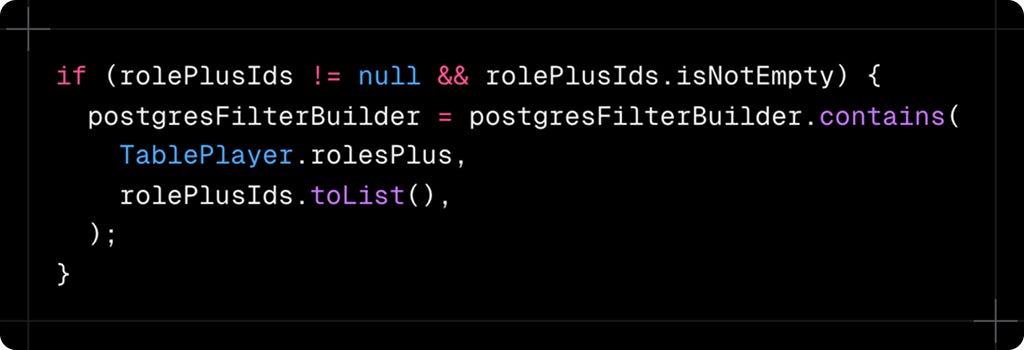
The contains method checks if the database array contains ANY of the provided values. This is perfect for our use case where a player might have multiple roles and we want to find players with at least one of the selected roles.
The Overlap Operator for Advanced Array Filtering
But what about playstyles? Here's where I discovered something powerful - the overlap operator:
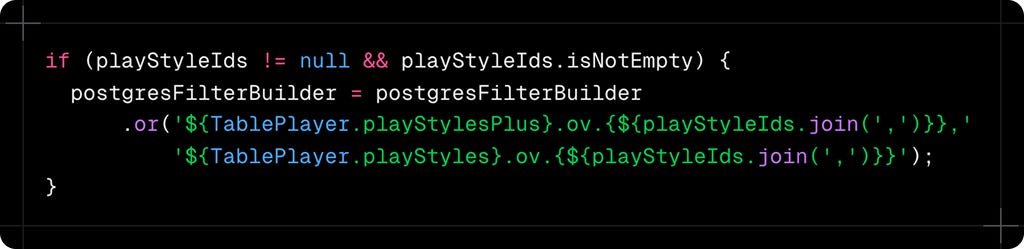
The .ov. operator checks if arrays overlap. This query finds players who have ANY of the selected playstyles in EITHER their regular or "plus" playstyle arrays. It's like asking "Does this player have Finesse Shot OR Long Shot in their regular abilities OR their upgraded abilities?"
This is player_details table from supabase, for your reference to understand that how playstyles and roles are stored for a player. Each row is one player.

Range Filters: The Edge Cases Matter
Rating filters seem simple but edge cases will bite you:
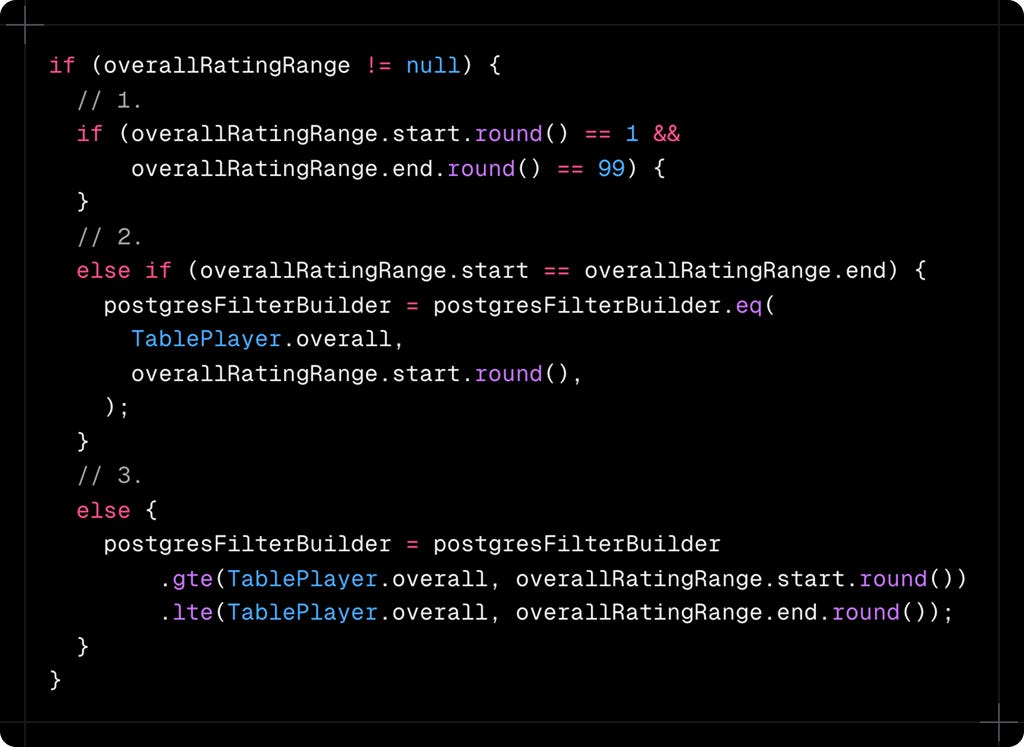
Why these edge cases? Users might slide both handles to the same value (wanting exactly 87-rated players). Or they might not touch the slider at all (1-99 range), in which case adding filters just slows things down.
When users haven’t touched range slider or when the start is 1 and end is 99, there is no need to apply filter as all players’ rating is in this range.
When start and end is equal, this means they want exactly same overall rating player, so here
eqis correct filter.When start and end is not same, we can use
gtestart andlteend on overall rating.
I would like you to watch this custom rating slider. I will be writing about it in future, so here is the glimpse. It can work as a range or a single value.
Video Tutorials
I have created a complete playlist of most important Supabase Filters. If you wish, you can watch them. All videos are < 5 minutes.
The Critical Order of Operations
After applying all filters, the ordering strategy is crucial:
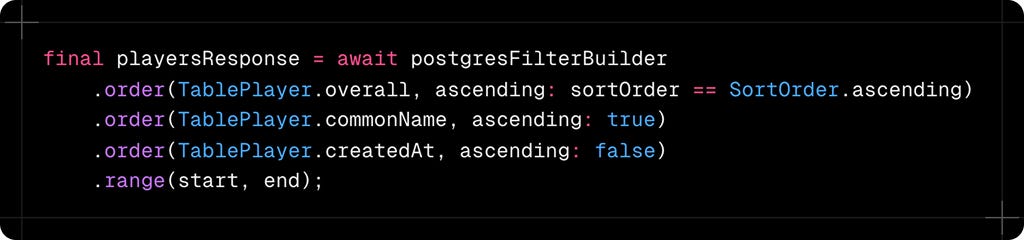
Why three order clauses? This creates deterministic sorting. Without it, players with the same rating appear in random order across pages, causing duplicates in pagination. The secondary and tertiary sorts ensure consistent ordering even when primary values match.
Pagination: The Silent Performance Killer
Notice the pagination calculation at the start:
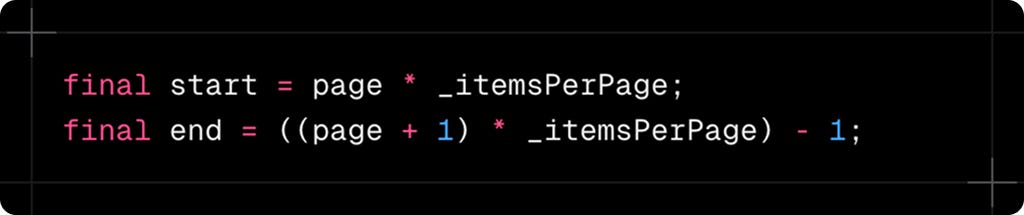
The range() method expects inclusive bounds. Getting this wrong means missing the last item on each page. But more importantly, this approach uses offset-based pagination, which has a hidden cost - Postgres still processes all skipped rows. For page 100 with 30 items per page, it processes 3,000 rows to return 30.
This is OK for few pages but as pages increase, cursor based pagination would make more sense. I will be updating this article where I will be comparing the performance of offset based and cursor based.
The Complete Pattern in Action
Let's trace through a real user scenario. A user wants to find:
Brazilian players (nation filter)
From Premier League or La Liga (league filter)
Who are strikers (position filter)
With 85+ overall rating (range filter)
Having the "Advanced Forward++" role (role filter)
Here's how our code handles it:
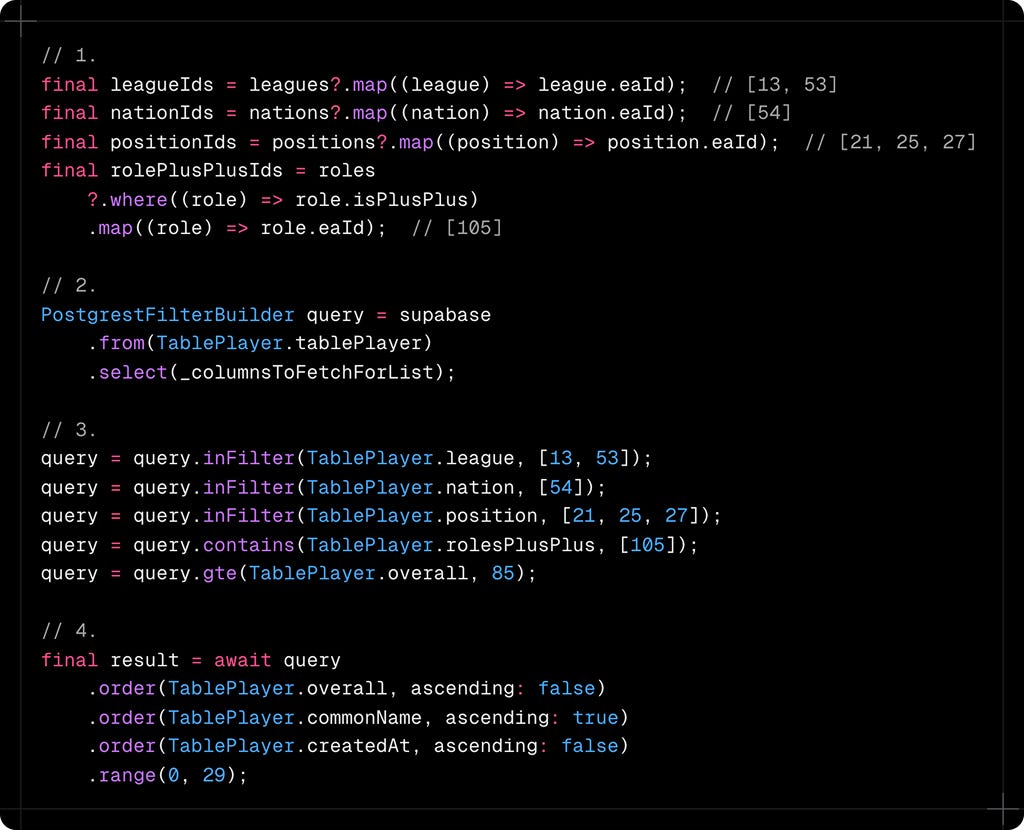
Transform complex objects to simple IDs
Build the query incrementally
Apply each filter with the appropriate method
Apply sorting and pagination
Each filter method is chosen specifically for its use case. Single values use eq, multiple values use inFilter, array fields use contains and ranges use gte/lte.
Performance Insights from Production
After implementing this pattern, here's what I observed in production:
Complex queries with 8+ active filters return in under 200ms. The key factors:
Using
inFilterinstead of OR chains reduced query time by 60%. More importantly they work as expectedProper compound indexes on commonly filtered columns (league, nation, position)
The three-level ordering strategy eliminated pagination duplicates
Caching the column list (
_columnsToFetchForList) instead of using wildcard
The Lessons Learned
Building complex Supabase filters taught me several principles:
Start with PostgrestFilterBuilder - It gives you a mutable query object you can build incrementally. This is cleaner than trying to chain everything in one go.
Choose the right operator for each filter type - Use inFilter for multiple IDs, contains for array membership, ilike for text search and standard comparison operators for ranges.
Handle edge cases explicitly - Empty arrays, null values and full ranges all need special handling. Don't assume your filters will always have sensible values.
Order matters for pagination - Multiple order clauses ensure deterministic results across pages. Without this, users see duplicate or missing results.
Wrap in proper error handling - Database queries fail. Network requests timeout. Plan for it from the start with Result types or similar patterns.
Next time you're building complex filters in Supabase, remember: it's not about chaining methods, it's about building a query systematically. Start with PostgrestFilterBuilder, choose the right operators, handle edge cases and always plan for failure. Your future self at 2 AM will thank you.
If you haven’t read about how all this started, I would recommend to understand the key insights that I shared in the previous two posts about my learnings and journey to make it to production on both mobile platforms - Android and iOS with Flutter.
